Tesseract字库编辑器使用说明
tip
- 该产品用于训练Tesseract的字库,基于jTessBoxEditor二次开发,简化操作,在处理字库上,更容易编辑
- 训练好的Tesseract字库,适用于EC的安卓、iOS USB版本、iOS脱机版本、鸿蒙Next版本等
下载安装
- 进入EC的网盘下载区域,找到【开发工具-Ocr资源文件夹】下载【EasyClick-TesseractOCR-字库编辑器.zip文件】
- 下载解压后,打开【tessocr-editor.exe】文件
- 注意:解压的路径不要有中文、空格等特殊字符,否则可能无法进行验证结果集
- 找不到下载网址,点这里 下载区域
训练字库
- 打开【tessocr-editor.exe】文件界面如下
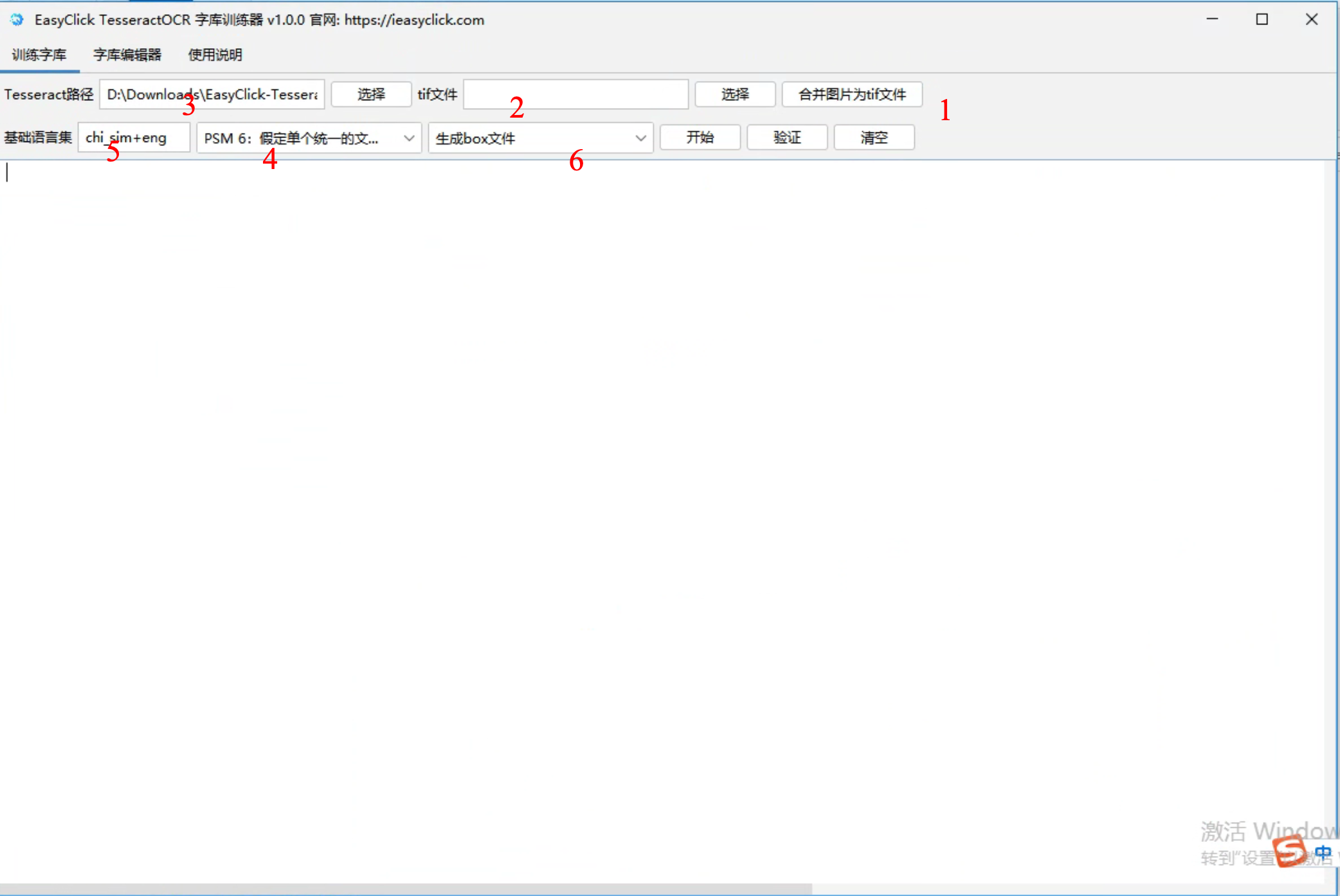
- Tesseract路径选项不用更改,默认已经选择了自带的tesseract训练库,如果更改,请选择到tesseract.exe文件
第一步:合并图片为tif文件按钮
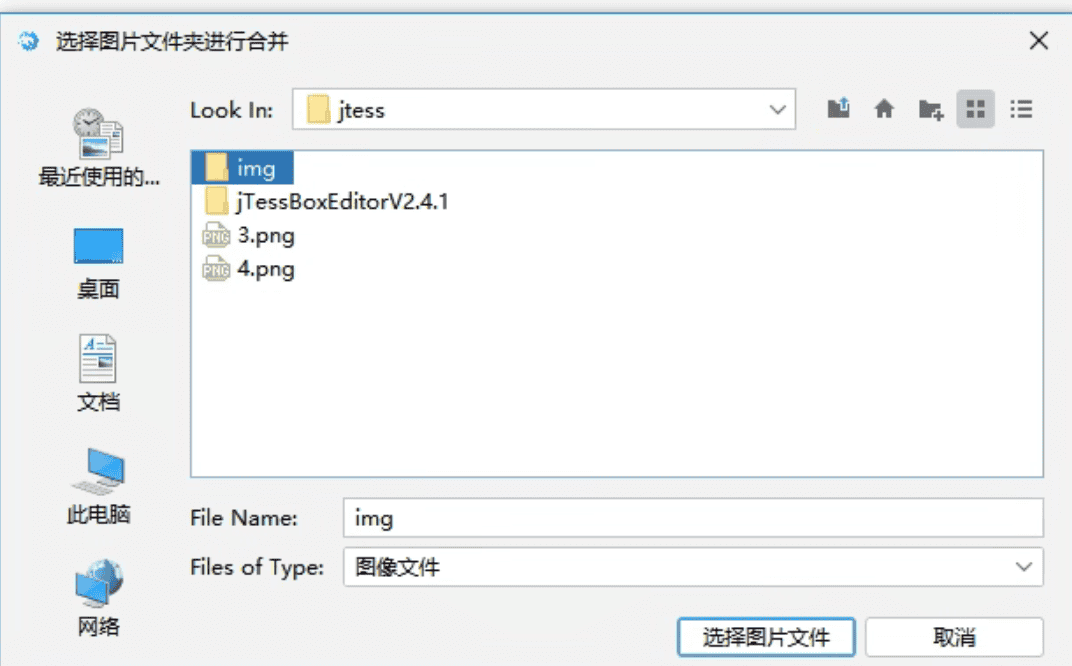
- 该功能是将jpg、png、bmp文件合并为tif图像文件,点击后可以选中一个文件夹或者选择一个图像文件进行合并
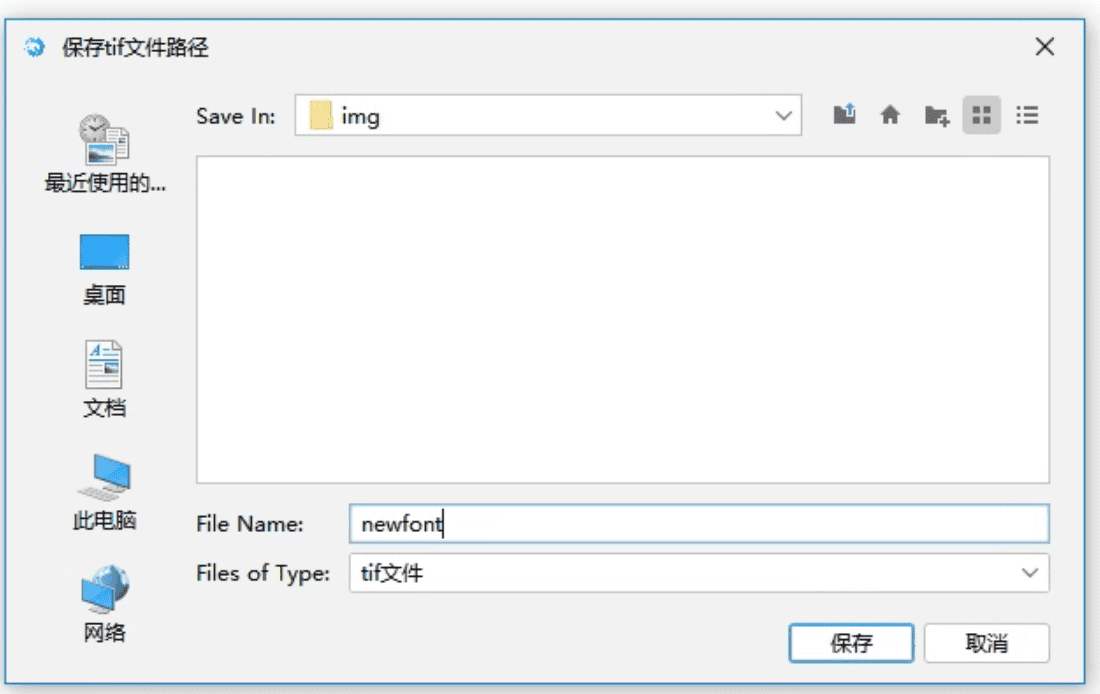
- 例如我们选择
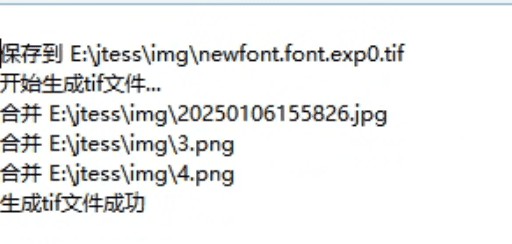
E:/jtess/img/文件夹,然后输入新字库名称为newfont进行合并,在日志界面会提示生成tif文件成功
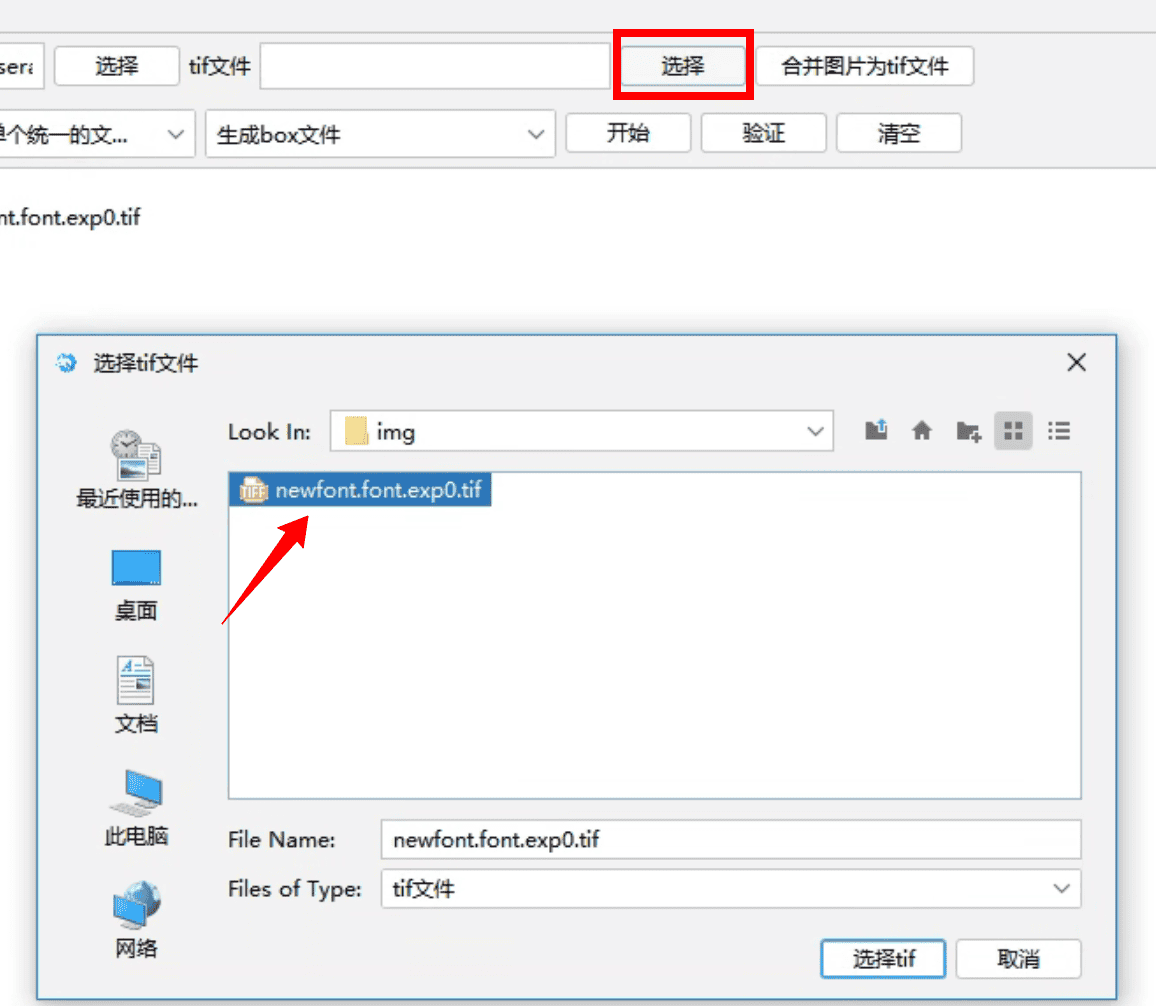
第二步:选择tif文件
- 点击
选择按钮, 进行选择tif文件
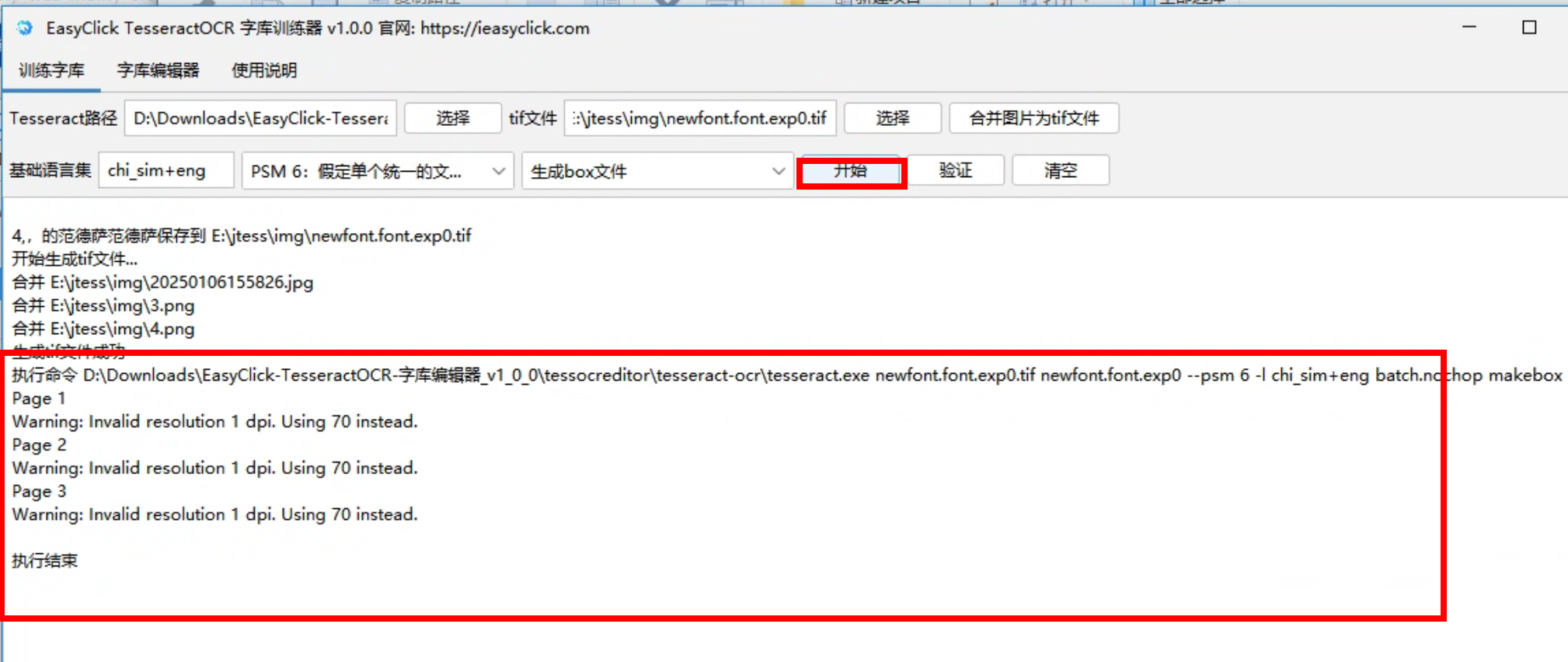
第三步:生成box字库文件
- 选择
生成box文件选项,点击开始按钮,这里默认PSM是6,基础语言集是中文加英文,也就是chi_sim+eng - 生成box的日志
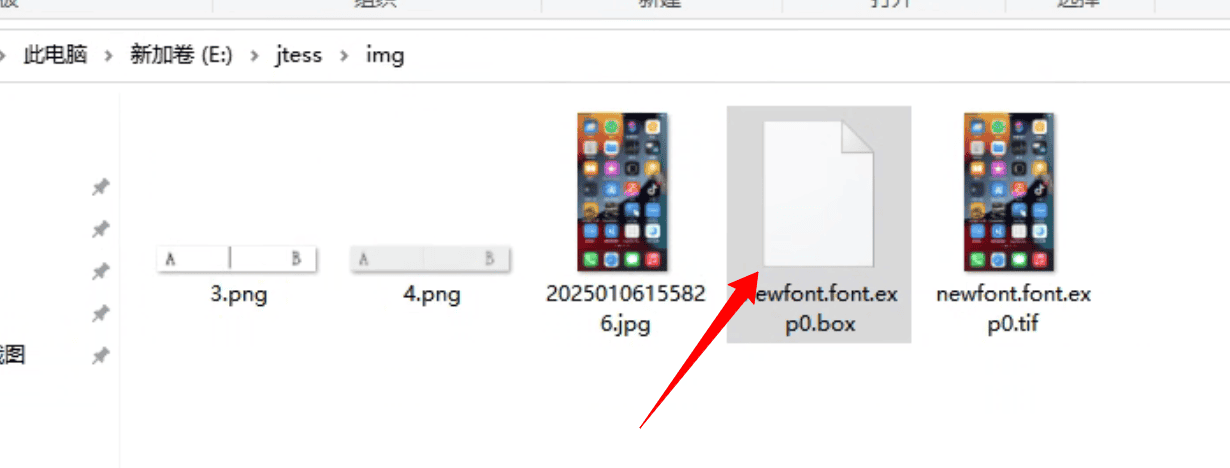
- 系统会在你的tif对应的文件夹生成一个系统文件名的box文件
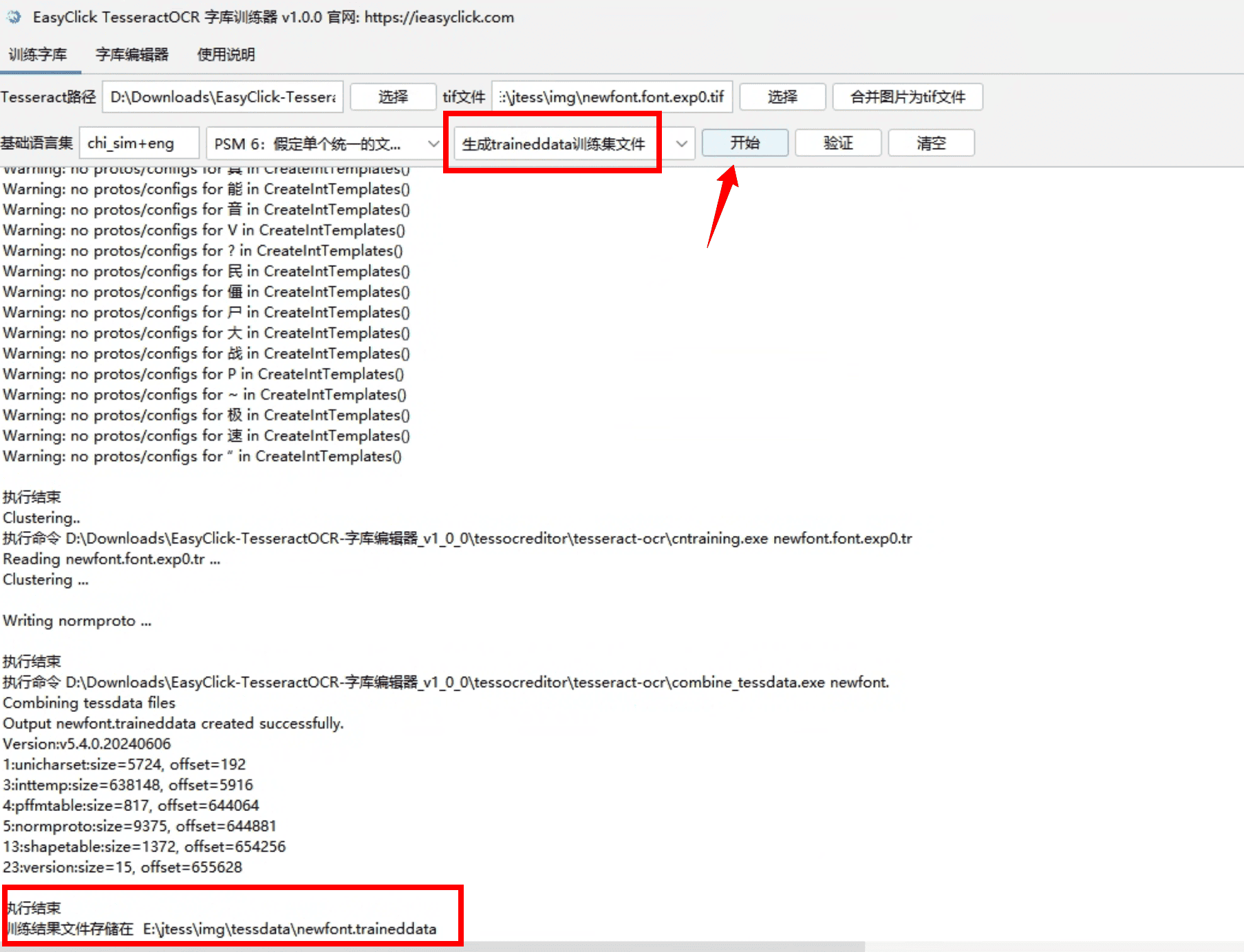
第四步:训练字库
- 这一步是生成tesseract的traineddata文件
- 选择
生成traineddata训练集文件选项,点击开始按钮,观察日志,就会在提示生成的traineddata文件夹路径
第五步: 验证
- 点击
验证按钮,选择一张图片,对tesseract生成的类库进行验证 - 也可以删除
基础语言集的值,进行验证 - 如果发现验证结果不如意,进入
字库编辑器选项,进行编辑字库后再次训练验证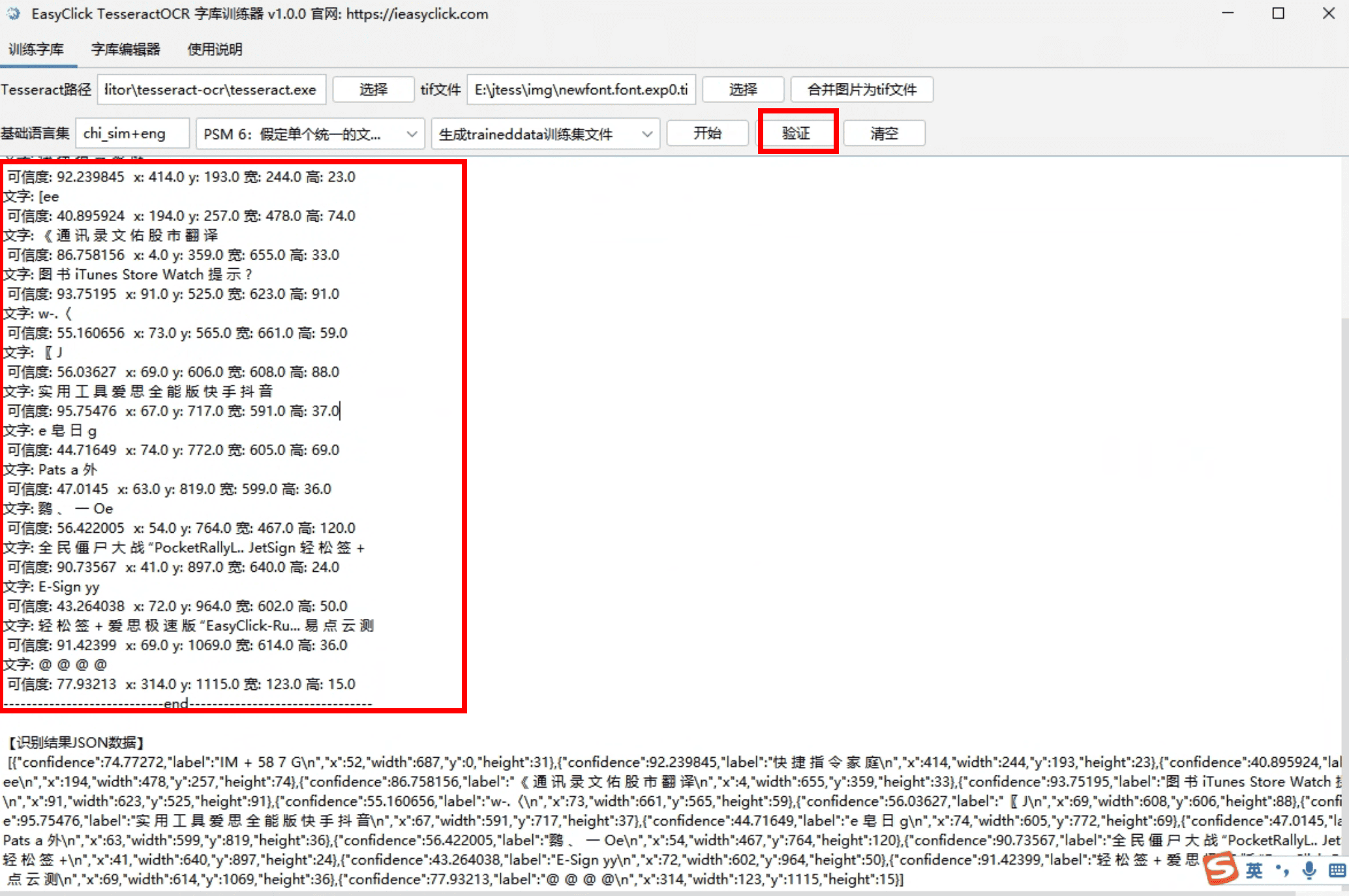
编辑字库
- 界面如下
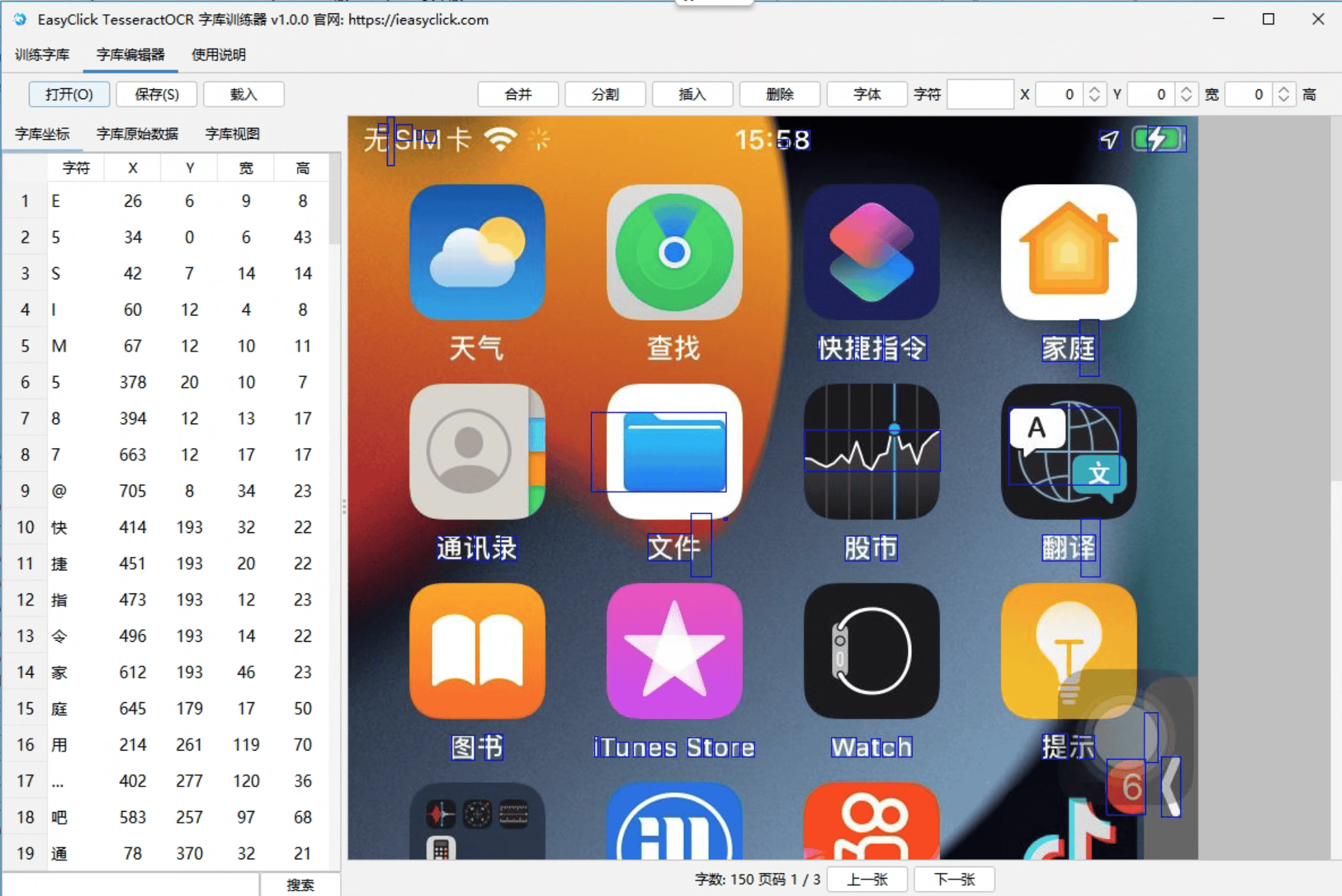
打开box文件
- 点击
打开按钮,快捷键是ctrl+o,选择一个tif文件,会自动打开box文件 - 左侧表格是字库和坐标,右侧是图片和字库的方框
编辑文字
- 双击表格中的文字进行编辑后回车,即可更改
- 或者更改顶部的字符一栏,更改文字和坐标
更改文字坐标框
- 选择 表格中的文字,在右边的图片中,文字会被用红色框住
- 拖动
红色框的斜箭头即可拖动框的大小 - 使用鼠标拖动红色框,更改框住的坐标
- 也可以使用
键盘的方向键��进行更改坐标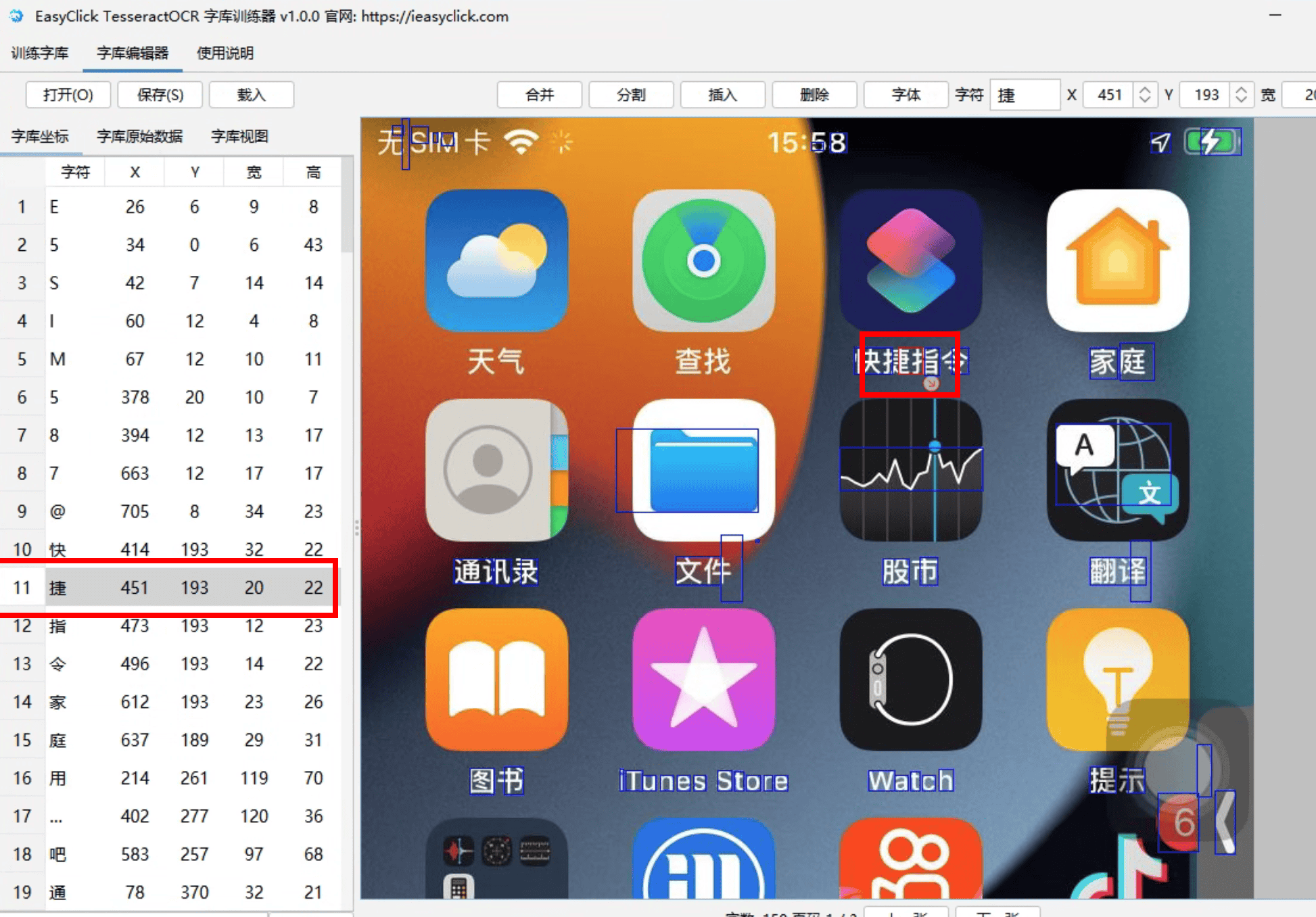
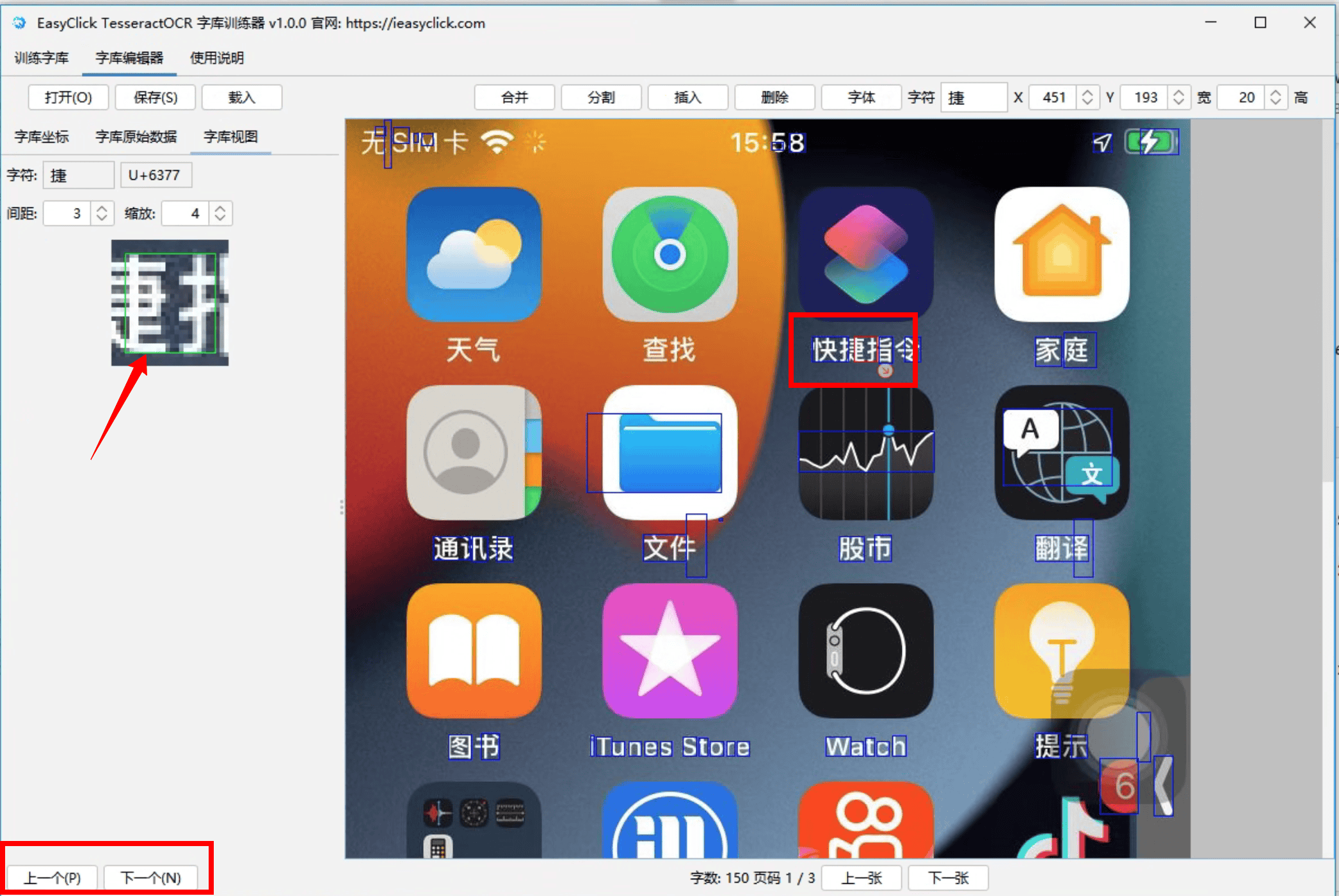
字库放大视图
- 点击字库视图一栏,使用
键盘的方向键进行移动红色框住的范围 - 使用
ctrl+方向键进行放大或者缩小框住的范围,一直到框住文字位置即可
图片编辑
- 该功能主要利用opencv的能力,对图片进行灰度和二值化,防止图片训练效果不好或者无法识别
其他功能
- 合并按钮:用来合并多个box文字
- 分割按钮:用来将一个box文字分割两个
- 插入按钮:插入新的box
- 删除按钮:删除不要的box
- 字体按钮:设置软件表格的字体,可以不用
- box字库表格右键菜单,也有部分功能
快捷键
ctrl+o打开box对应的tif文件ctrl+s保存编辑的box文件ctrl+p或者alt+p切换到上一个字ctrl+n或者alt+n切换到下一个字方向键移动文字的框ctrl+方向键或者alt+方向键扩大或者缩小文字框的范围鼠标拖动:拖动文字框鼠标拖动斜箭头:放大缩小文字框ctrl+d或者alt+d上一张图片ctrl+g或者alt+g下一张图片
使用
- 编辑好字库,并且重新训练为traineddata文件,即可按照tessocr的教程使用训练的字库了
保存
- 关闭软件之前 一定要保存编辑的box数据,防止丢失
常见问题
- 验证结果不成功
- 可能是解压zip的文件路径包含了中文或者特殊字符,更改文件夹路径为英文即可
- 软件打开闪退
- 可能是因为系统缺少vc组件,去网盘找到vc组件进行安装重启电脑后重新打开软件
- 训练的时候出现 FAILURE! couldn’t find a matching blob
- “couldn’t find a matching blob”通常是因为Tesseract无法识别图像中的特定形状或特征。
- 解决这个问题有以下几种方法:
- 提高图像质量:确保输入图像清晰无噪声,适当调整亮度和对比度。Tesseract对高质量的图像有更好的识别效果。
- 使用预处理:在识别前进行图像预处理,如二值化、去噪、倾斜校正等,可以提高识别准确率。
- 调整参数:Tesseract有许多可调参数,如
psm(页面分割模式)和oem(OCR引擎模式)。通过试验不同参数组合,可能找到适合特定场景的最佳设置。 - 调整box字库的范围