PPOCR-ONNX使用说明
tip
- 本OCR产品是免费的
- 本产品基于PaddleOCR开发,支持PPOCR-v4和PPOCR-v5模型,目前可以在Windows上运行
- 本产品目的是对外提供ocr接口,可以给EC 安卓,iOS USB,iOS 脱机版,鸿蒙Next进行接口调用,并返回OCR结果
下载软件
- 进入软件下载区的任何一个网盘进行下载,点击软件下载区
- 下载路径在网盘的
Ocr资源文件夹中ppocr-windows-x64开头的zip文件,下载完成解压即可,解压路径不要有中文和特殊字符
软件使用
- 双击
ppocr-monitor.exe开始,这个程序是用来守护ocr程序的,如果ocr退出,会被主动拉起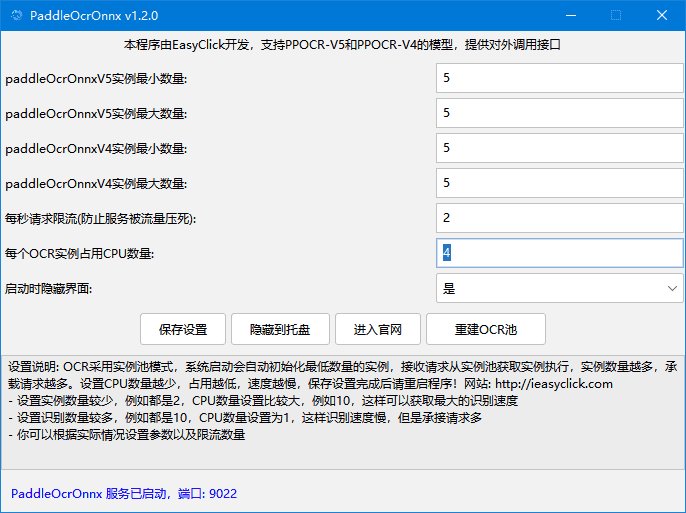
- 软件打开后,底部会提示端口和服务器启动状态
- 系统采用OCR实例池的模式,提高效率和并发量
- paddleOcrOnnxV5实例最小数量 代表最小实例化的v5模型数量
- paddleOcrOnnxV5实例最大数量 代表实例化v5上限
- v4实例数量含义也是类似
- 每秒限流请请求,代表能够承接的请求数量,因为OCR需要时间,根据实际情况自己设定
- 每个OCR实例占用CPU数量,越大代表OCR速度越快,CPU占用越高,建议 CPU数量*最大实例 不要超过你的电脑CPU,否则会变成100%CPU占用
- 设置后,进行保存然后重启软件
- 重建OCR池: 代表释放之前的OCR实例,重新生成,这个操作会释放之前的内存占用
- 启动时隐藏界面,代表启动的时候在后台运行,隐藏到托盘
接口调用
- 系统自带了http调用接口,默认端口是 9022
- 上传图像文件调用接口: http://127.0.0.1:9022/devapi/ocrOnnxFile
- POST JSON base64图像数据接口: http://127.0.0.1:9022/devapi/ocrOnnxBase64
- 如果你是局域网就将地址的 127.0.0.1 换成服务所在电脑的IP
- 如果你希望是公网,可以将程序部署到公网,或者通过frp进行代理转发到你的内网 ,就将地址中的127.0.0.1换成你公网IP
ocrOnnxFile 请求例子
- 这里以EC 安卓为例子,iOS和鸿蒙Next是一样的方式请求
function test_http_ppocr() {
if (!startEnv()) {
loge("自动化启动失败,结束脚本")
exit()
}
if (!image.requestScreenCapture(10000, 0)) {
loge("申请截图权限失败,检查是否开启后台弹出,悬浮框等权限")
exit()
}
//申请完权限至少等1s(垃圾设备多加点)再截图,否则会截不到图
sleep(1000)
for (let i = 0; i < 1; i++) {
let img = image.captureFullScreenEx()
if (!img) {
loge("截图失败")
sleep(1000)
continue
}
// 使用的识别模型 paddleOcrOnnxV5 代表PPOCR-V5 , paddleOcrOnnxV4 代表 PPOCR-V4
let ocrType = "paddleOcrOnnxV5";
// padding 图像外接白框,用于提升识别率,文字框没有正确框住所有文字时,增加此值。默认 10。
let padding = 50;
// maxSideLen 如果输入图像的最大边大于max_side_len,则会按宽高比,将最大边缩放到max_side_len。默认为 0
let maxSideLen = 0;
try {
let url = `http://192.168.2.19:9022/devapi/ocrOnnxFile?ocrType=${ocrType}&padding=${padding}&maxSideLen=${maxSideLen}`
console.log(`request url ${url}`)
// 保存文件到 /sdcard/tb.png
image.saveTo(img, "/sdcard/tb.png")
let file = {"file": "/sdcard/tb.png"}
console.time(1)
let result = http.httpPost(url, {}, file, 20 * 1000, {})
logd("请求耗时: {} ms", console.timeEnd(1))
if (!result) {
logw("未识别到结果")
sleep(1000)
continue
}
logd("ocr结果-> " + result)
result = JSON.parse(result).data;
for (let i = 0; i < result.length; i++) {
let value = result[i]
logd("文字 : " + value.label+ " confidence: "+value.confidence + " x: " + value.x + " y: " + value.y + " width: " + value.width + " height: " + value.height)
}
sleep(1000)
} catch (e) {
logd(e)
} finally {
image.recycle(img)
}
}
}
test_http_ppocr()
ocrOnnxBase64 请求例子
function test_http_ppocr_base() {
if (!startEnv()) {
loge("自动化启动失败,结束脚本")
exit()
}
if (!image.requestScreenCapture(10000, 0)) {
loge("申请截图权限失败,检查是否开启后台弹出,悬浮框等权限")
exit()
}
//申请完权限至少等1s(垃圾设备多加点)再截图,否则会截不到图
sleep(1000)
for (let i = 0; i < 1; i++) {
let img = image.captureFullScreenEx()
if (!img) {
loge("截图失败")
sleep(1000)
continue
}
// 使用的识别模型 paddleOcrOnnxV5 代表PPOCR-V5 , paddleOcrOnnxV4 代表 PPOCR-V4
let ocrType = "paddleOcrOnnxV5";
// padding 图像外接白框,用于提升识别率,文字框没有正确框住所有文字时,增加此值。默认 10。
let padding = 50;
// maxSideLen 如果输入图像的最大边大于max_side_len,则会按宽高比,将最大边缩放到max_side_len。默认为 0
let maxSideLen = 0;
try {
let url = `http://192.168.2.19:9022/devapi/ocrOnnxBase64`
console.log(`request url ${url}`)
let base = image.toBase64(img)
let data = {
"ocrType":ocrType,
"padding":padding,
"maxSideLen":maxSideLen,
"data":base,
}
console.time(1)
let result = http.postJSON(url, data, 20 * 1000, {})
logd("请求耗时: {} ms", console.timeEnd(1))
if (!result) {
logw("未识别到结果")
sleep(1000)
continue
}
logd("ocr结果-> " + result)
result = JSON.parse(result).data;
for (let i = 0; i < result.length; i++) {
let value = result[i]
logd("文字 : " + value.label+ " confidence: "+value.confidence + " x: " + value.x + " y: " + value.y + " width: " + value.width + " height: " + value.height)
}
sleep(1000)
} catch (e) {
logd(e)
} finally {
image.recycle(img)
}
}
}
test_http_ppocr_base();
常见问题
- ppocr打开闪退
- 到网盘下载vc类库安装,然后重启电脑
- 识别速度慢
- 将每个OCR占用CPU实例放大,缩小实例数量,获得最快的 识别速度
- 内存占用高
- 减少OCR实例数量,或者 加内存 ,加CPU